Part 1 - Disaster Recovery with SRM and vSphere Replication
Abstract
The company I work for has needs for disaster recovery but there is also external demands for it. The company not being very big has so far not been able to implement any automated disaster recovery solution although we do have a documented disaster recovery plan. The plan regardless of how good or bad it is isn't tested in a long time and the RTO (Recovery Time Objective) is wished by management to be days but I can't see that it is anything else than weeks.Since we virtualized our production system I've been looking at VMware vCenter Site Recovery Manager as a driver but the cost array based replication has stopped any attempts dead in their tracks. VMware vSphere® Replication has been around for a while now and we hope that it's hardened enough for a slightly bigger production critical implementation.
In this article I will try to document and explain how we experiment, design and implement disaster recovery and even more important, in my opinion, disaster avoidance based on SRM and vSphere Replication.
The Setup
The intended target is our production systems. This setup consists of a number of data centers geographically distributed over the globe. The intention is to fail all of our production systems to one location i.e. DC 3 (PF - primary failover) and to fail the DC 3 itself to a secondary failover DC 4 (SF - secondary failover). Please note that if DC3 has a disaster DC1, DC2 and DC4 will no longer have a failover site and DC3 will failover to DC4.

The setup obviously has latency of various degrees between the sites but that is not a major concern, at least not at this time. The major concern that I have is the bandwidth consumption of vSphere Replication. Some data centers suffer from absolutely ludicrous bandwidth costs, and my fear is that the amount of data replicated will be too high so I believe that the test system would have to include some WAN-acceleration and bandwidth throttling in the end.
The test setup concists is our staging environment that I will setup to failover to a small temporary system. Most likely the failover system won't be able to handle the entire system in a failover but I hope that it will be enough to start the minimal set of services needed to prove a successful failover of the entire system. At least the exercise will be capable of answering questions about how to setup SRM, bandwidth requirements for replication, and a ton of other questions.
Installation
I will not describe the installation of the appliances vCenter, vSphere Replication or Site Recovery Manager other than very briefly since there are described in detail by VMware in:
- ESXi and vCenter Server 5.1 Documentation > vSphere Installation and Setup
- VMware vSphere Replication Administration vSphere Replication 5.1
- Site Recovery Manager Installation and Configuration vCenter Site Recovery Manager 5.1
Installation phases
Basic requirements for installing SRM is pretty obvious. You need to have two sites with its own HW, each site needs its own vCenter and its own SRM installation.
- Install vCenter in both locations.
- vCenter inventory configuration
- Install and configure SRM database
- SRM installation at both locations
- SRM plug-in installation
- Pair the sites
Use fully qualified domain names during the installation to avoid confusion and to achieve a reliable setup.
vSphere Replication
vSphere Replication is bundled with vSphere with no additional cost although in this form it's in a per VM basis. With SRM you get the orchestration and management of vSphere Replication on a higher level. vSphere Replication manage disk replication in a storage agnostic way i.e. you can replicate between different storage vendors, local disks or what ever you need.
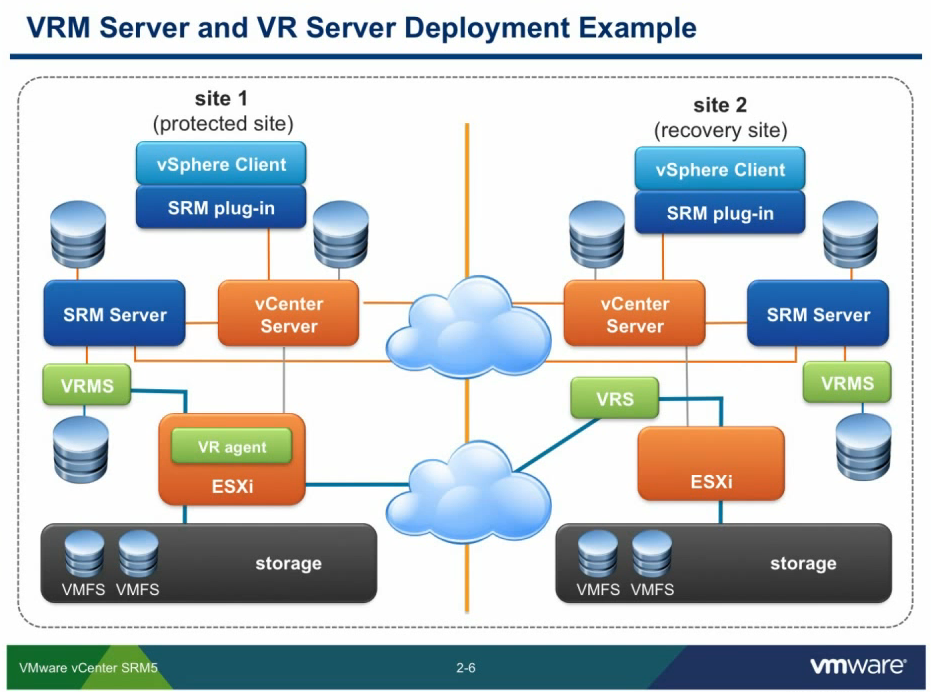 |
| (c) 2012 VMware Inc |
The magic comes from the VR agent installed in each ESXi host. It is recording the actual changes, on block level, to be replicated per VM when the RPO limit is approaching.
For instructions on the installation in a SRM scenario please see the excellent explanation in:
Inventory Mapping
Inventory mapping is simply house keeping making sure that the oranges aren't mixed with apples. If you get a fruit salad of VM, folders, datastores and networks in a disaster situation you surely gone be even more sad than before. So to make you're life simple spend some time mapping up the protected site so that its keept separate from the things living in the recovery site.
Protection Groups
What is it? A group of machines that failover together.
In an array based replication scenario the protection groups pretty much is defined by the datastores and the VM's living together in a datastore since you failover entire datastores.
When we use vSphere Replication gets a slightly different meaning. vSphere Replication is not dictated by the storage setup its dictated by you. This means that you can freely create protection groups for VM's that should failover together from a service perspective.
Configuring vSphere Replication
Once you completed the Installation above you can start setting up the vSphere Replication. This can be done either by selecting the vm to replicate and choose vSphere Replication in the drop down menu or by selecting the vSphere Replication tab and clicking on the Configure Replication link.
The replication wizard will popup and ask a number of question:
 |
| Configure Replication - page 1 |
 |
| Configure Replication - page 2 |
 |
| Configure Replication - page 3 |
 |
| Configure Replication - page 4 |
Final page - review the specified options and go for it.
Recovery Plan
The recovery plan or rather the plans lets you specify how to recover from different disasters. When looking at this its not the cataclysmic disaster that's the common one rather it is the smaller ones that a set of firewalls burn up and you can't handle the traffic. Power outages in parts of the datacenter. When you analyze what can go wrong and how it affects you're business its likely that you will end up with a number of smaller scenarios.
Furthermore you can, and most likely should, specify the start order of VM's that has been recovered. Basically it makes sense to build the foundation before you raise the walls and put up the roof.
The recovery plan also allows you to shutdown VM's running at the recovery site to free up resources in a failover scenario.
The most notable thing about recovery plans is that the plan should be created at the recovery site to protect against cataclysmic disasters at the protected site.
References
- Part 1 - SRM5 Concepts/Architecture
- Part 2 - Installing SRM5
- Part 3 - Site Pairing
- Part 4 - Storage Replication - part 1
- Part 5 - Storage Replication - part 2
- Part 6 - Inventory Mapping
- Part 7 - Protection Groups
- Part 8 - Creating a Recovery Plan
- Part 9 - Testing a Recovery Plan
- Part 10 - SRM Failover
- Part 11 - SRM Failback
Comments
smoothly and successfully.